Architecture Overview
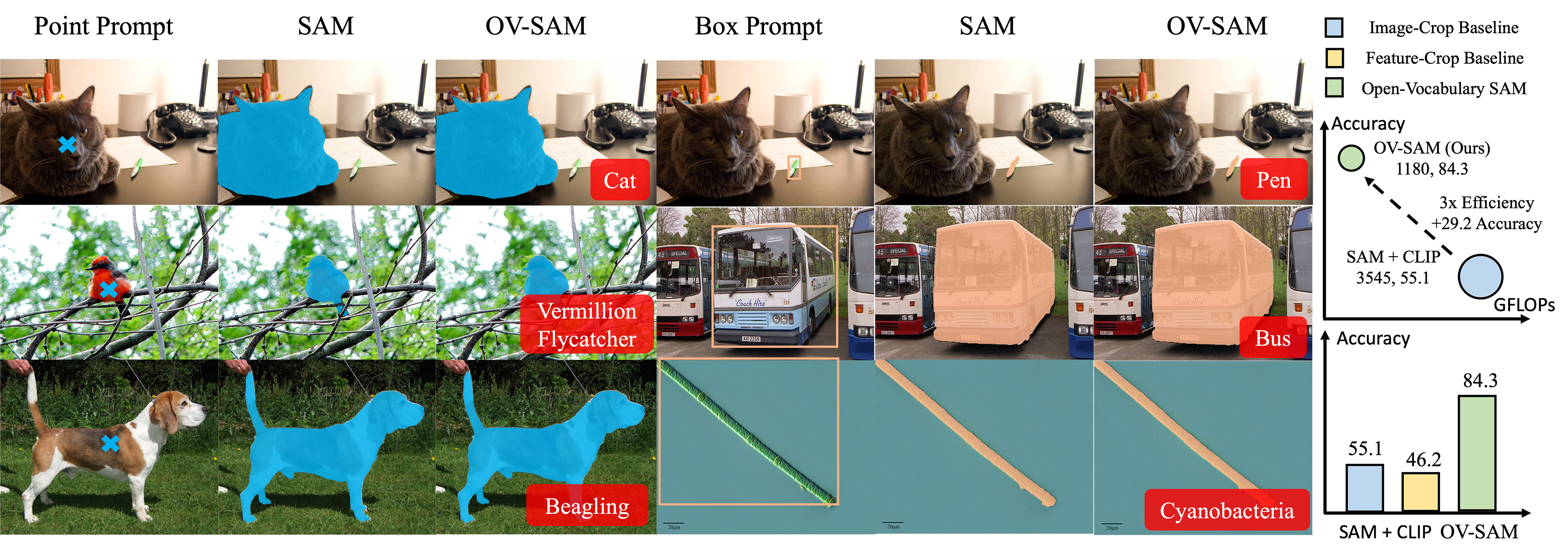
The Open-Vocabulary Segment Anything Model (OVSAM) is designed to bridge the gap between class-agnostic interactive segmentation and open-vocabulary object recognition. It enhances the foundational Segment Anything Model (SAM) with the ability to not only segment any object but also recognize it from a vast vocabulary of over 20,000 classes.
This is achieved through a novel two-way knowledge transfer mechanism between SAM and CLIP (Contrastive Language-Image Pre-Training).
Key Components
The core of OVSAM consists of two primary knowledge transfer modules:
1. SAM2CLIP: Transferring Segmentation Knowledge to CLIP
This module enriches CLIP's understanding of visual concepts with the fine-grained localization and segmentation abilities of SAM. It works as follows:
- Feature Distillation: SAM's powerful image features, which are adept at capturing object boundaries and shapes, are distilled into the CLIP model.
- Learnable Transformer Adapters: Lightweight transformer adapters are introduced into the CLIP backbone. These adapters are trained to integrate SAM's spatial and segmentation cues directly into the CLIP feature hierarchy.
This process effectively teaches the CLIP model to "see" objects with the same level of detail as SAM, improving its region-specific feature representation without compromising its original recognition capabilities.
2. CLIP2SAM: Transferring Recognition Knowledge to SAM
This module endows the SAM model with the ability to associate its generated masks with semantic labels from CLIP's open-vocabulary knowledge base.
- Enhanced Mask Decoder: The knowledge learned during the SAM2CLIP stage is transferred back into SAM's mask decoder.
- Open-Vocabulary Classification: The mask decoder is enhanced with a classification head that can project mask embeddings into the same feature space as CLIP's text embeddings. This allows for direct comparison and labeling of a segmented region with any text prompt.
By integrating CLIP's semantic knowledge, the SAM model evolves from a pure segmentation tool into a powerful interactive recognition system.