Open-Vocabulary SAM & RWKV-SAM
This project introduces two innovative models, Open-Vocabulary SAM (OVSAM) and RWKV-SAM, designed to advance the capabilities of image segmentation. OVSAM extends the Segment Anything Model (SAM) to simultaneously perform interactive segmentation and recognize over twenty thousand classes. RWKV-SAM explores a more efficient architecture for high-quality, high-speed segmentation.
![]()
Core Projects
Open-Vocabulary SAM (OVSAM)
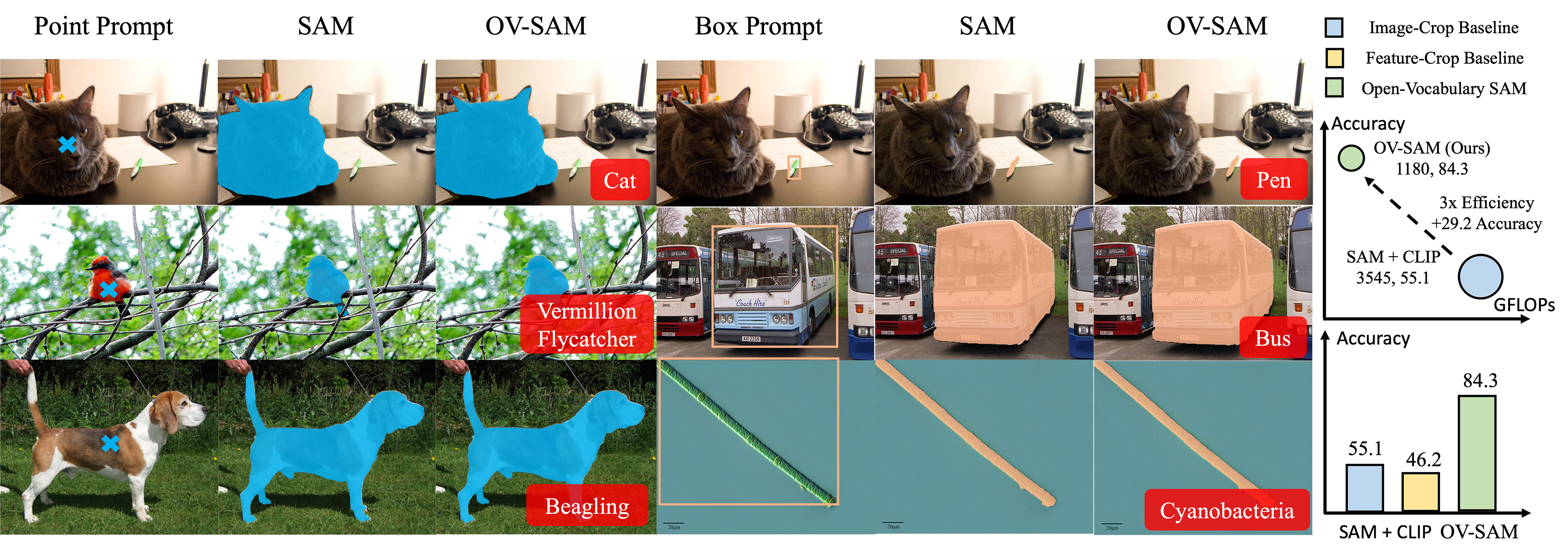
OVSAM is a SAM-inspired model designed for simultaneous interactive segmentation and recognition. It leverages two unique knowledge transfer modules:
- SAM2CLIP: Adapts SAM's segmentation knowledge into the CLIP model via distillation and learnable transformer adapters.
- CLIP2SAM: Transfers CLIP's vast recognition knowledge into SAM, enhancing its ability to identify and label segmented objects.
This dual-transfer approach allows OVSAM to segment and recognize a vast vocabulary of object classes interactively.
RWKV-SAM
RWKV-SAM introduces an efficient segmentation backbone and a complete training pipeline to enable high-quality segmentation with significantly improved performance. Compared to equivalent transformer-based models, RWKV-SAM achieves more than a 2x speedup while delivering superior segmentation results across various datasets.
For more details, please see the RWKV-SAM documentation.
📰 News
Jul. 2, 2024: Open-Vocabulary SAM has been accepted by ECCV 2024.Jun. 27, 2024: The RWKV-SAM code and model have been released. Read the paper.
📚 Citation
If you find this work useful for your research, please consider citing our papers:
@inproceedings{yuan2024ovsam,
title={Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively},
author={Yuan, Haobo and Li, Xiangtai and Zhou, Chong and Li, Yining and Chen, Kai and Loy, Chen Change},
booktitle={ECCV},
year={2024}
}@article{yuan2024mamba,
title={Mamba or RWKV: Exploring High-Quality and High-Efficiency Segment Anything Model},
author={Yuan, Haobo and Li, Xiangtai and Qi, Lu and Zhang, Tao and Yang, Ming-Hsuan and Yan, Shuicheng and Loy, Chen Change},
journal={arXiv preprint},
year={2024}
}